This article gives a simple tutorial of implementing custom paging on the SQL Server side. Here we will just see how paging techniques have been evolving since Microsoft SQL Server 2000.
This article is intended to answer the following questions:
- What is new in Microsoft SQL 2012 for paging?
- How was paging implemented in earlier versions of Microsoft SQL Server 2008/2005; before SQL Server 2012's OFFSET & FETCH clauses?
- How was paging implemented in Microsoft SQL 2012 differently in terms of performance?
- How can we get the same performance in earlier versions of Microsoft SQL Server 2008/2005?
- What is the benefit of implementing paging at the SQL Server side manually though there are many ASP.Net Data controls available that implement it themselves?
Once we understand the advantage of custom paging over default paging, we will go for wiring it up with ASP.Net and the C# language. So I am limiting the scope of this article to understanding the custom paging techniques.
Setting the environment to be implemented
To implement paging in SQL Server 2012 (to have a hand on exposure), I assume you already have a running version of it. If not, you can download the express edition free of cost from Microsoft's website at: http://www.microsoft.com/sqlserver/en/us/editions/2012-editions/express.aspx
Overview
Huge data with paging has been a big headache on the Developer's head. There is a default paging option available with some data controls. These controls do manage paging automatically without writing so much code but provide poor performance. This default paging is handled at the page level (in the .Net environment) and consumes memory. Few known techniques have been impaired with these controls to enhance the performance. But they still give bad performance over custom-paging.
In general practice, to handle a Page index change, the following mechanism/trick is applied:
- Get all records on every call from the database and directly assign it to the DataControl. This is commonly known as Default-paging.
- Get all the records for the first time only and store them into some state variables like ViewState/memory etc.
- Fetch all records for the first time only and cache them. From future calls the data/record is fetched from the cache instead of the database. This technique is also used with DataSource controls like sqlDataSource etc.
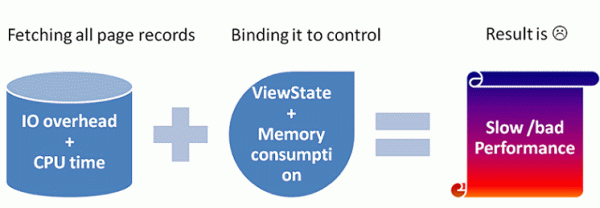
We will analyse the first option. In this all records are fetched for just showing a single page record to the user. Other page records are not shown, then why, fetch all records from the database on each page index change? It is going to take CPU time as well as IO read for fetching all records. It provides very bad performance.
In the second practice, a huge quantity of records/data is saved in memory that hampers the performance in terms of a limited amount of memory for many users.
In the third approach, where the cache is implemented is just minimizing the database hits. All other problems still exists there. This also requires memory to keep/maintain the dataset cache and cause problems. Secondly it serves stale data/records. Microsoft clarifies it as "However, you should not cache objects that hold resources or that maintain state that cannot be shared among multiple requests, such as an open DataReader object."
So programmers started looking for better approaches/techniques and zeroed on the database level. This custom paging approach fetches only page-size records for a particular page. It prevents excessive reads for the database engine and saves CPU time. The DataControl requires counting the total-records so that they can show page numbers and this one is also queried along with query.
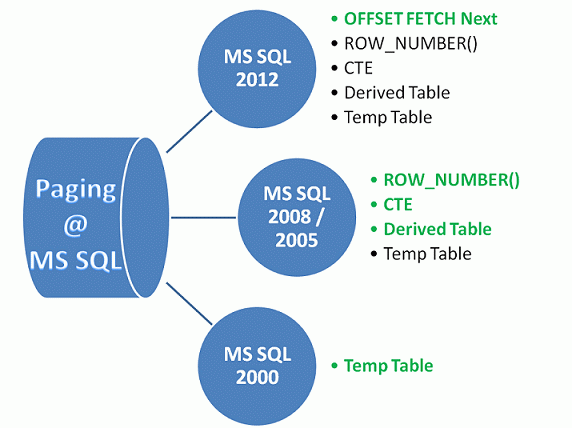
In earlier version of Microsoft SQL, there were no customized clauses or functions for paging. So many programmers tried many approaches at the database level to implement the requirements. Doing some hacks/tricks (use of a temp table etc) in earlier versions like Microsoft SQL Server 2000 was much better than implementing default paging or using cache/state variables.
So, let us start with the Microsoft SQL Server 2012 edition.
Microsoft SQL Server 2012 edition
In this new version/edition, we have a new clause "OFFSET FETCH Next" that extends the existing ORDER BY clause. This is something like a ready-made option for paging. Before this there was no direct function/clause to implement custom paging. OFFSET specifies the number of rows to skip and FETCH specifies the number of rows to return (after skipping rows provided by the OFFSET clause). The following syntax is taken from Microsoft's MSDN for a better view of it:
OFFSET { integer_constant | offset_row_count_expression } { ROW | ROWS }
FETCH { FIRST|NEXT } <rowcount expression> { ROW|ROWS } ONLY
Implementing custom paging in Microsoft SQL Server 2012 is very easy compared to earlier versions. It reads only the required number of rows and thus saves the IO as well CPU time that occurs from reading excess rows. It works like the TOP clause with Order By. So it gives better performance than the temp table mechanism.
A Simple usage syntax is as:
CREATE PROCEDURE dbo.uspGetPageRecords
(
@OffSetRowNo INT,
@FetchRowNo INT
)
AS
SELECT colName1, colName2, colName3, colName4 FROM tblMyTableName
ORDER BY colNameForSorting
OFFSET ( @OffSetRowNo-1 ) * @FetchRowNo ROWSFETCH NEXT @FetchRowNo ROWS ONLY
GO
And a simple example is:CREATE PROCEDURE dbo.uspGetPageRecords
(
@PageNo INT,
@RecordsPerPage INT
)
AS
--The offset specified in a OFFSET clause may not be negative.
--So check & set the initial for avoiding negative OFFSET
IF @PageNo < 1
SET @PageNo = 1
SELECT AutoID, Name, City, RegistrationDate FROM tblUserMaster
ORDER BY RegistrationDate
OFFSET ( @PageNo - 1 ) * @RecordsPerPage ROWS
FETCH NEXT @RecordsPerPage ROWS ONLY
GO
The following are the limitations of using Offset Fetch:
- Fetch Next can't be used standalone, it requires Offset
- Offset can't be used standalone, it requires order by
- Top can't be combined with offset fetch next in the same query expression
Microsoft SQL Server 2008/2005 edition
Microsoft had introduced a new function ROW_NUMBER() with Microsoft SQL 2005/2008. In addition to this ROW_NUMBER(), two other approaches, Common Table Expression (CTE) and Derived Table concepts, were given.
The following is an approach with the help of CTE and ROW_NUMBER():
SELECT AutoID, Name, City, RegistrationDate,
, ROW_NUMBER() OVER (ORDER BY RegistrationDate ) AS rowNumber
SELECT AutoID, Name, City, RegistrationDate,
WHERE rowNumber > 0 AND rowNumber <= 10
And if you don't want to hit your database twice for the Total record count or you don't want a second select/read then the following approach would be the better option. If you are using an Object/DTO then you can assign this total record count and do the stuff. In this approach two sequence numbers are created with ROW_NUMBER(). The second one is ordered in reverse of the first one and due to this at each row level the total no of records = the sum of these two sequence fields - 1. So if you create your DTO, you just need to have one additional property/variable for holding this record total.
SELECT AutoID, Name, City, RegistrationDate,
ROW_NUMBER() OVER(ORDER BY RegistrationDate) AS rowNumber ,
ROW_NUMBER() OVER(ORDER BY RegistrationDate DESC) AS totalRows
SELECT AutoID, Name, City, totalRows + rowNumber -1 AS TotalRecords
WHERE rowNumber BETWEEN 1 AND 10
Wrap up
For a small number of records, one can use the default GridView paging option but with huge records I would like to suggest use of custom-paging at the SQL Server side.
To finish this tutorial, we will summarize as:- What is new in Microsoft SQL 2012 for paging?
- Microsoft SQL Server 2012 comes with two extended clauses of ORDER BY and they are OFFSET & FETCH. These two clauses are used with Order By clause and make our SQL Engines to read only the specified number of records given with Fetch after the Offset value.
- How paging was being implemented in earlier version of Microsoft SQL Server2008/2005 before SQL Server 2012's OFFSET & FETCH clauses?
- In Microsoft SQL 2008 & 2005 there were many ways to implement paging. These two versions have Derived Table, CTE (Common Table Expression) and famous ROW_NUMER() for getting our job done easily as compared to the Microsoft SQL Server 2000 version. In this version many experts use #tempTable in combination with these clauses to achieve better performance.
- In Microsoft SQL Server 2000, paging were being done by creating a temporary table #table with an Identity column along with our data columns. In the second term we query records with order and get the page records. This was very expensive but much better than client side paging (paging in the .Net environment).
- How is paging implemented in Microsoft SQL 2012 differently in terms of performance?
- Using OFFSET & FETCH clauses, we save beyond the limit reads and thus our SQL Engine stops reading once we get the specific required number of records. This was what we were missing and implementing with our hacks (using the TOP clause etc.) in the Microsoft SQL Server 2008/2005 versions. So it is good in terms of performance.
- It is very simple, clean and understandable. We simply provide Offset and Fetch counts, and it does everything else automatically.
- How can we get the same performance in earlier versions of Microsoft SQL Server 2008/2005?
- There are some hacks/tricks and we can have the same performance as in earlier versions of Microsoft SQL Server 2008/2005. If we analyse the mechanism behind OFFSET & FETCH Count, we find that it is working as TOP (n) of our SELECT clause. So we can use TOP (n) with appropriate paging approaches and can get the same performance. For code samples, refer to:
http://sqlblogcasts.com/blogs/sqlandthelike/archive/2012/04/26/offset-without-offset.aspx
- What is the benefit of implementing paging at the SQL Server side manually though there are many ASP.Net Data controls available that implement it themselves?
- There are many data controls, like GridView, that provides paging and we need not to write a SQL statement/query for that. But it causes a heavy performance issue.
- We also don't stop reading records from the SQL Engine after meeting our record count for a page. We read all records and thus CPU time plus IO read requires time and overload.
- And the total records requires more memory in our .Net environment (in DataSet, DataTable, DataReader), so here again performance is heavily impacted.